Web Scraping Using Selenium
What is web scraping?
Web scraping is a technique for extracting information from the internet automatically using a software that simulates human web surfing.
How is web-scraping useful?
Web scraping helps us extract large volumes of data about customers, products, people, stock markets, etc. It is usually difficult to get this kind of information on a large scale using traditional data collection methods. We can utilize the data collected from a website such as e-commerce portal, social media channels to understand customer behaviors and sentiments, buying patterns, and brand attribute associations which are critical insights for any business.
Getting Started
Since we have defined our purpose of scraping, let us delve into the nitty-gritty of how to actually do all the fun stuff! Before that below are some of the housekeeping instructions regarding installations of packages.
- Python version: We will be using Python 3.0
- Selenium package: You can install selenium package using the following command
!pip install selenium
- Chrome driver: Please install the latest version of chromedriver from here.
Please note you need Google Chromeinstalled on your machines to work through this illustration.
The first and foremost thing while scraping a website is to understand the structure of the website. We will be scraping Edmunds.com, a car forum. This website aids people in their car buying decisions. People can post their reviews about different cars in the discussion forums (very similar to how one posts reviews on Amazon). We will be scraping the discussion about entry level luxury car brands.
We will scrape ~5000 comments from different users across multiple pages. We will scrape user id, date of comment and comments and export it into a csv file for any further analysis.
Let’s begin
We will first import important packages in our Notebook
#Importing packages
import pandas as pd
from selenium import webdriver
Let’s now create a new instance of google chrome. This will help our program open an url in google chrome.
# from os import path
# home = path.expanduser("~")
# driverPath = path.join(home, 'Source/chromedriver')
# driver = webdriver.Chrome(driverPath)
# from webdriver_manager.microsoft import EdgeChromiumDriverManager
# driver = webdriver.Edge(EdgeChromiumDriverManager().install())
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
[WDM] -
[WDM] -
[WDM] - ====== WebDriver manager ======
[WDM] - ====== WebDriver manager ======
====== WebDriver manager ======
[WDM] - Current google-chrome version is 96.0.4664
[WDM] - Current google-chrome version is 96.0.4664
Current google-chrome version is 96.0.4664
[WDM] - Get LATEST chromedriver version for 96.0.4664 google-chrome
[WDM] - Get LATEST chromedriver version for 96.0.4664 google-chrome
Get LATEST chromedriver version for 96.0.4664 google-chrome
[WDM] - Driver [/Users/bk/.wdm/drivers/chromedriver/mac64/96.0.4664.45/chromedriver] found in cache
[WDM] - Driver [/Users/bk/.wdm/drivers/chromedriver/mac64/96.0.4664.45/chromedriver] found in cache
Driver [/Users/bk/.wdm/drivers/chromedriver/mac64/96.0.4664.45/chromedriver] found in cache
Let’s now access google chrome and open our website. By the way, chrome knows that you are accessing it through an automated software!
driver.get('https://forums.edmunds.com/discussion/2864/general/x/entry-level-luxury-performance-sedans/p1')
Woha! We just opened an url from python notebook.
So, how does our web page look like?
We will inspect 3 items (user id, date and comment) on our web page and understand how we can extract them.
- User id: Inspecting the userid, we can see the highlighted text represents the XML code for user id.
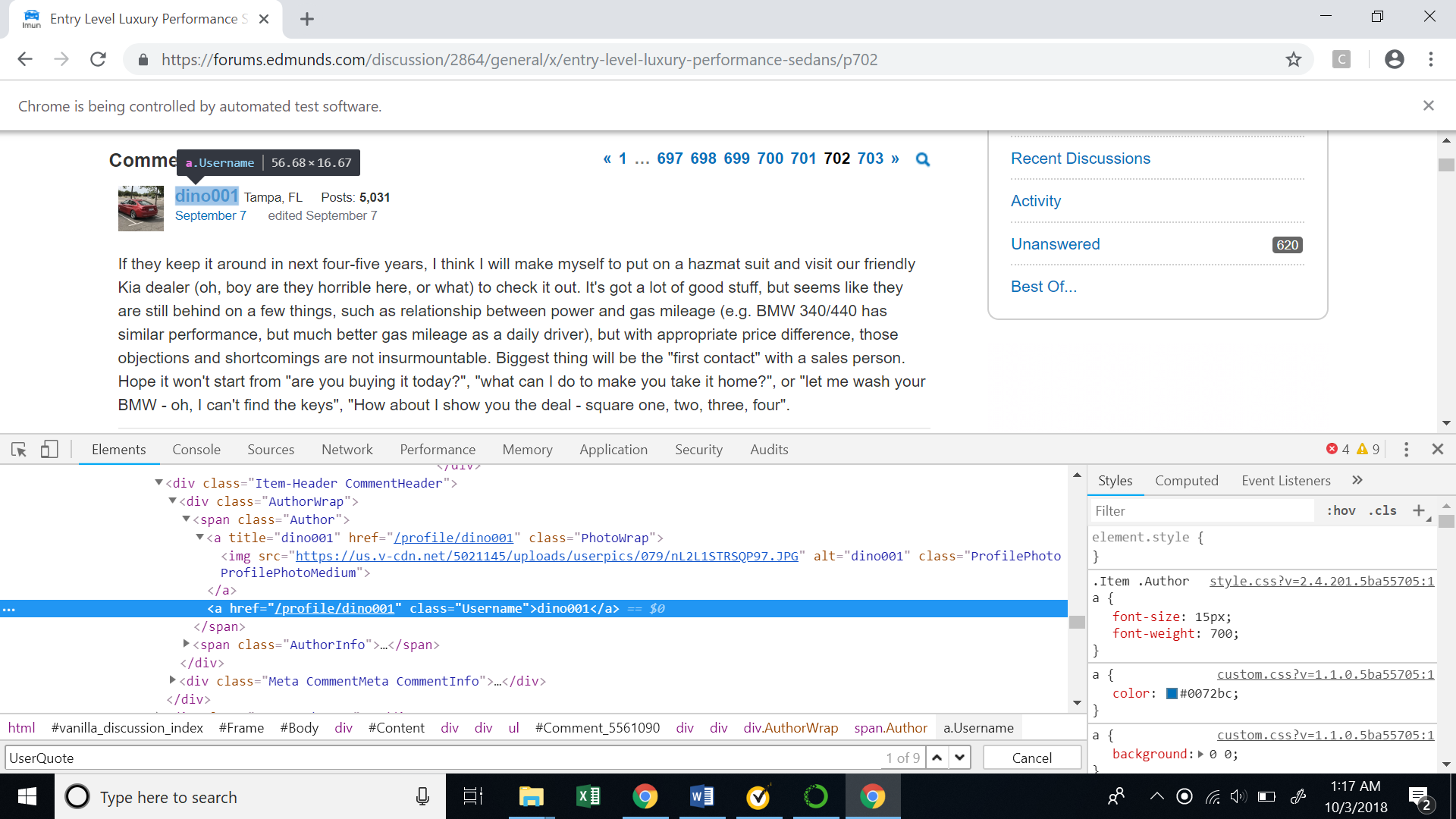
The XML path (XPath)for the userid is shown below. There is an interesting thing to note here that the XML path contains a comment id, which uniquely denotes each comment on the website. This will be very helpful as we try to recursively scrape multiple comments .
//*[@id=”Comment_5561090"]/div/div[2]/div[1]/span[1]/a[2]
If we see the XPath in the picture, we will observe that it contains the user id ‘dino001’.
How do we extract the values inside a XPath?
Selenium has a function called “find_elements_by_xpath”. We will pass our XPath into this function and get a selenium element. Once we have the element, we can extract the text inside our XPath using the ‘text’ function. In our case the text is basically the user id (‘merc1’).
userid_element = driver.find_elements(By.XPATH, '//*[@id="Comment_1726631"]/div/div[2]/div[1]/span[1]/a[2]')
userid_element
[<selenium.webdriver.remote.webelement.WebElement (session="de4b05220f981f7f4d63c45c478541ca", element="3a2d2809-d889-4a6a-824a-944d7f5d94e4")>]
userid = userid_element[0].text
userid
'merc1'
- Comment Date: Similar to the user id, we will now inspect the date when the comment was posted.
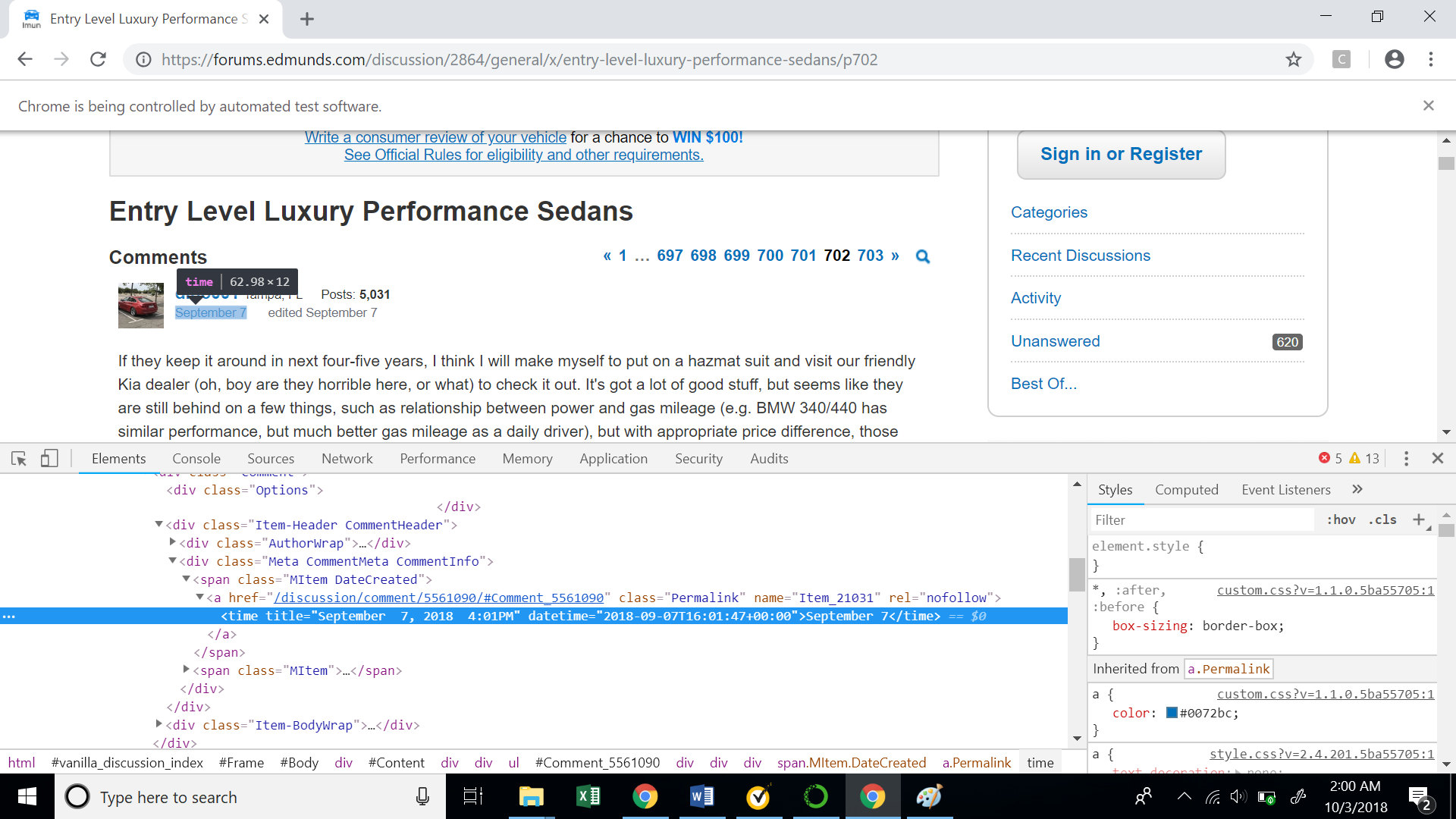
Let’s also see the XPath for the comment date. Again note the unique comment id in the XPath.
//*[@id="Comment_5561090"]/div/div[2]/div[2]/span[1]/a/time
So, how do we extract date from the above XPath?
We will again use the function “find_elements_by_xpath” to get the selenium element. Now, if we carefully observe the highlighted text in the picture, we will see that the date is stored inside the ‘title’ attribute. We can access the values inside attributes using the function ‘get_attribute’. We will pass the tag name in this function to get the value inside the same.
user_date = driver.find_elements_by_xpath('//*[@id="Comment_5561090"]/div/div[2]/div[2]/span[1]/a/time')[0]
date = user_date.get_attribute('title')
- Comments: Lastly, let’s explore how to extract the comments of each user.
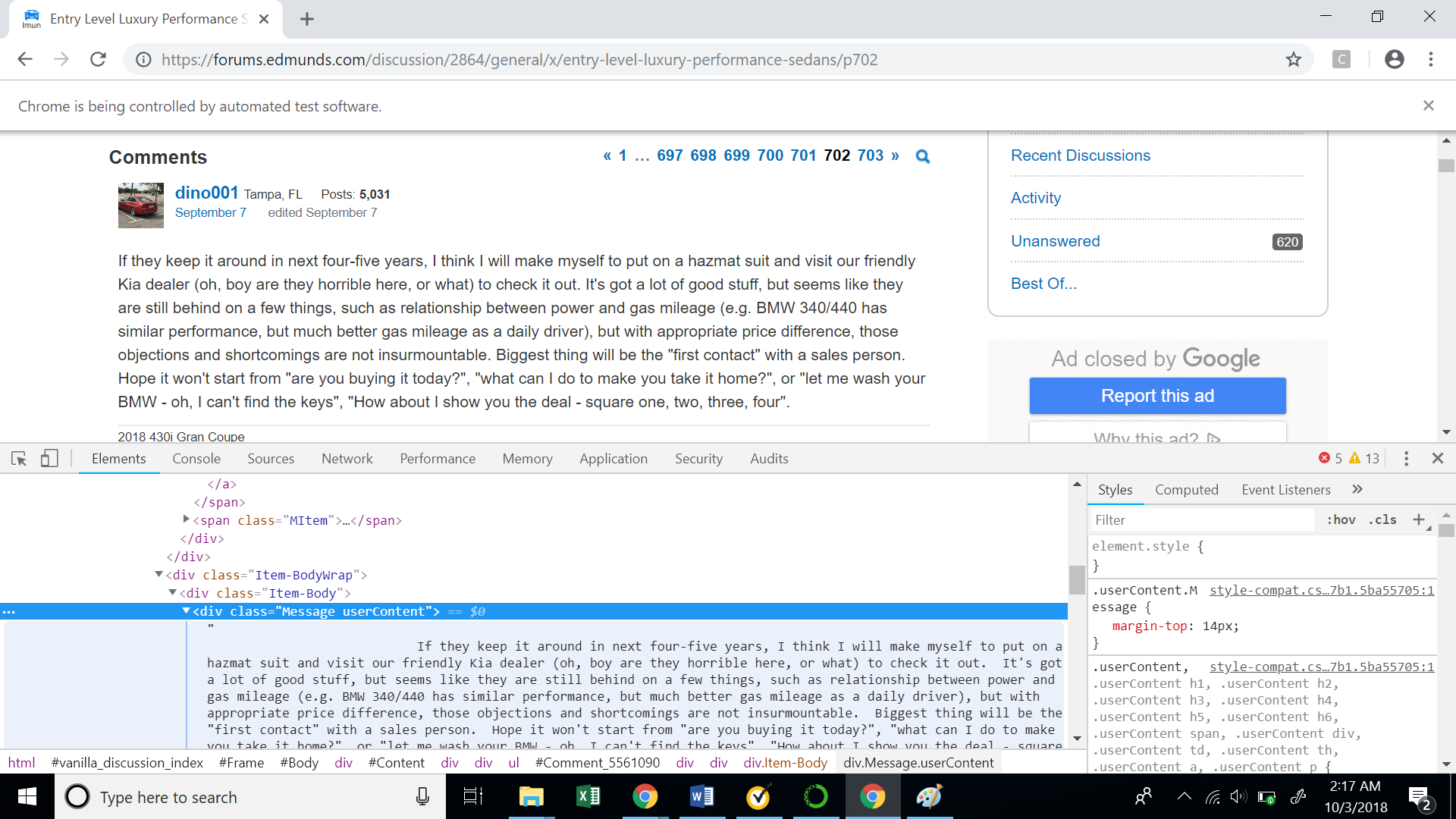
Below is the XPath for the user comment.
//*[@id="Comment_5561090"]/div/div[3]/div/div[1]
Once again, we have the comment id in our XPath. Similar to the userid we will extract the comment from the above XPath
user_message = driver.find_elements_by_xpath('//*[@id="Comment_5561090"]/div/div[3]/div/div[1]')[0]
comment = user_message.text
We just learnt how to scrape different elements from a web page. Now how to recursively extract these items for 5000 users?
As discussed above, we will use the comment ids, which are unique for a comment to extract different users data. If we see the XPath for the entire comment block, we will see that it has a comment id associated with it.
//*[@id="Comment_5561090"]
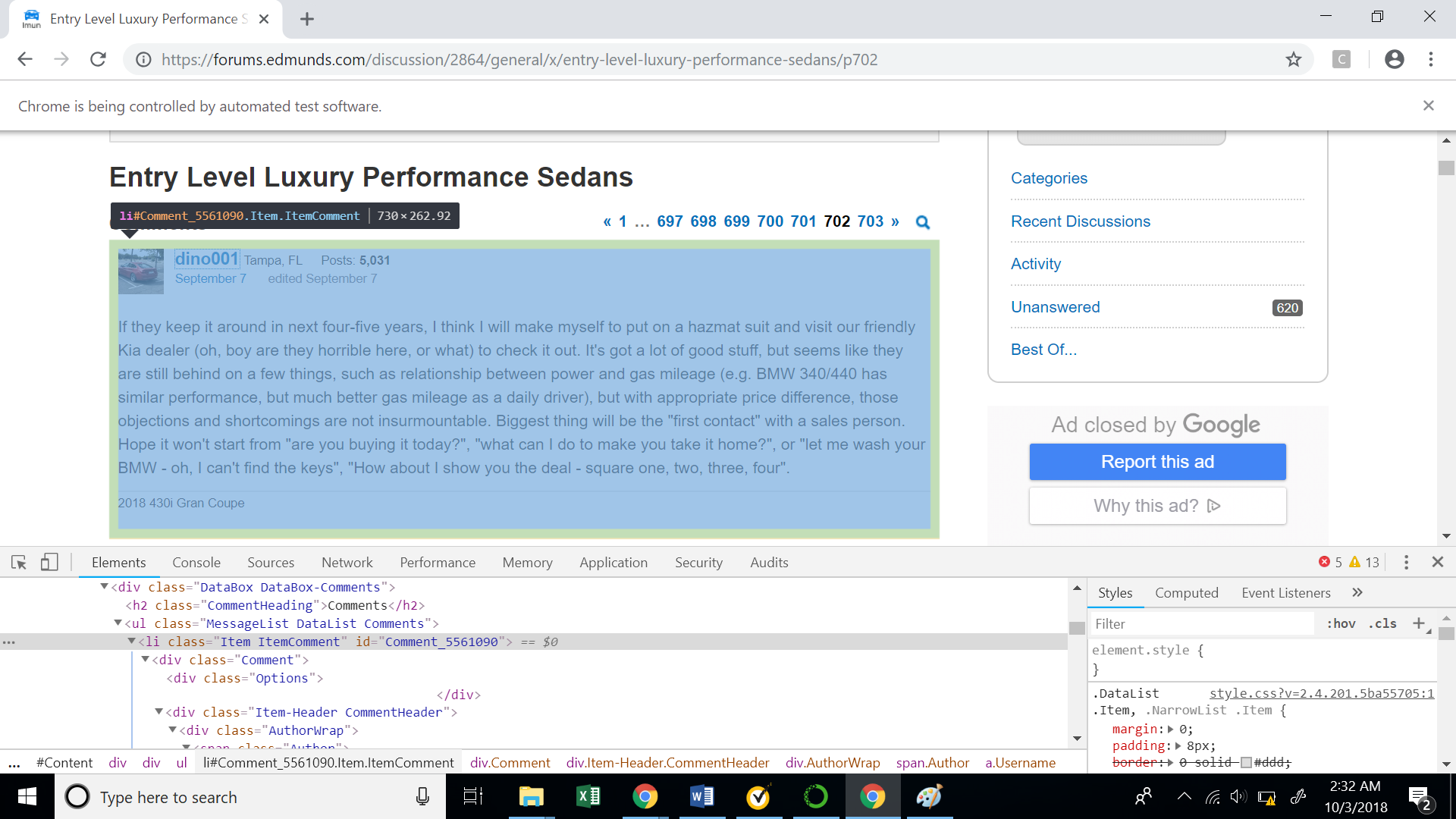
The following code snippet will help us extract all the comment ids on a particular web page. We will again use the function ‘find_elements_by_xpath’ on the above XPath and extract the ids from the ‘id’ attribute.
This code gives us a list of all the comment ids from a particular web page.
from selenium.webdriver.common.by import By
ids = driver.find_elements(By.XPATH, "//*[contains(@id,'Comment_')]")
comment_ids = []
for i in ids:
comment_ids.append(i.get_attribute('id'))
print(comment_ids)
['Comment_1738047', 'Comment_1738152', 'Comment_1738262', 'Comment_1738371', 'Comment_1738478', 'Comment_1738589', 'Comment_1738699', 'Comment_1738809', 'Comment_1738919', 'Comment_1739025', 'Comment_1739133', 'Comment_1739239', 'Comment_1739348', 'Comment_1739457', 'Comment_1739566', 'Comment_1739669', 'Comment_1739779', 'Comment_1739888', 'Comment_1739998', 'Comment_1740218', 'Comment_1740328', 'Comment_1740438', 'Comment_1740548', 'Comment_1740653', 'Comment_1740760', 'Comment_1740869', 'Comment_1740981', 'Comment_1741091', 'Comment_1741198', 'Comment_1741299', 'Comment_1741407', 'Comment_1741512', 'Comment_1741613', 'Comment_1741723', 'Comment_1734276', 'Comment_1741943', 'Comment_1742054', 'Comment_1742164', 'Comment_1742272', 'Comment_1742383', 'Comment_1742484', 'Comment_1742554', 'Comment_1742664', 'Comment_1742884', 'Comment_1742966', 'Comment_1726633', 'Comment_1726738', 'Comment_1726849', 'Comment_1726960', 'Comment_1727067']
How to bring all this together?
Now we will bring all the things we have seen so far into one big code, which will recursively help us extract 5000 comments. We can extract user ids, date and comments for each user on a particular web page by looping through all the comment ids we found in the previous code.
Below is the code snippet to extract all comments from a particular web page.
# from selenium.webdriver.chrome.service import Service
# from webdriver_manager.chrome import ChromeDriverManager
# driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
comments = pd.DataFrame(columns = ['Date','user_id','comments'])
comment_ids = []
for page in range(1, 2, 1):
driver.get(f'https://forums.edmunds.com/discussion/2864/general/x/entry-level-luxury-performance-sedans/p{page}')
ids = driver.find_elements(By.XPATH, "//*[contains(@id,'Comment_')]")
for i in ids:
comment_ids.append(i.get_attribute('id'))
for x in comment_ids:
#Extract dates from for each user on a page
user_date = driver.find_elements(By.XPATH, '//*[@id="' + x +'"]/div/div[2]/div[2]/span[1]/a/time')[0]
date = user_date.get_attribute('title')
#Extract user ids from each user on a page
userid_element = driver.find_elements(By.XPATH, '//*[@id="' + x +'"]/div/div[2]/div[1]/span[1]/a[2]')[0]
userid = userid_element.text
#Extract Message for each user on a page
user_message = driver.find_elements(By.XPATH, '//*[@id="' + x +'"]/div/div[3]/div/div[1]')[0]
comment = user_message.text
#Adding date, userid and comment for each user in a dataframe
comments.loc[len(comments)] = [date,userid,comment]
comments.head()
| Date | user_id | comments | |
|---|---|---|---|
| 0 | March 24, 2002 9:54PM | merc1 | I personally think that with a few tweaks the ... |
| 1 | March 24, 2002 11:06PM | fredvh | I am debating a new purchase and these two are... |
| 2 | March 25, 2002 9:02AM | blueguydotcom | Great handling, RWD, excellent engine and the ... |
| 3 | March 25, 2002 3:04PM | hungrywhale | And no manual tranny. That may not matter to y... |
| 4 | March 25, 2002 4:44PM | riez | One beauty of BMW 3 Series is that there are s... |